
A few weeks ago, I wrote about my transition from advertising technology into hiring technology and the moment I realized that modern hiring systems were operating on an incredibly thin data layer.
What struck me at the time was how much labor market infrastructure still depended on resumes, job descriptions, and keywords to make decisions about human potential. Compared to the world I had just left in advertising technology — where audience-level data had fundamentally transformed how marketplaces operated — the hiring ecosystem felt surprisingly underdeveloped.
This week, I had the opportunity to continue that conversation while speaking at the Digital Credentials CoLab Micro Summit, hosted by Open edX, and I found myself thinking less about the existence of the missing data layer itself and more about what happens once that layer begins reaching meaningful scale.
Because I increasingly believe the core challenge facing Learning and Employment Records (LERs) is not whether they create value.
It is whether the ecosystem can build enough trusted, interoperable infrastructure for that value to become operationally unavoidable.
One of the ideas I discussed during the session was the tendency for people in the LER ecosystem to frame employer adoption as primarily an awareness or acceptance problem. Understandably, institutions investing in digital credentials often ask a version of the same question:
“If we do all this work, will employers actually use it?”
My answer continues to be yes.
But probably not in the way many people expect.
I do not think employers are going to adopt Learning and Employment Records because they suddenly become philosophically passionate about credentials themselves. Employers adopt systems that help them make better decisions, reduce uncertainty, improve workflows, and identify talent more effectively.
That distinction matters.
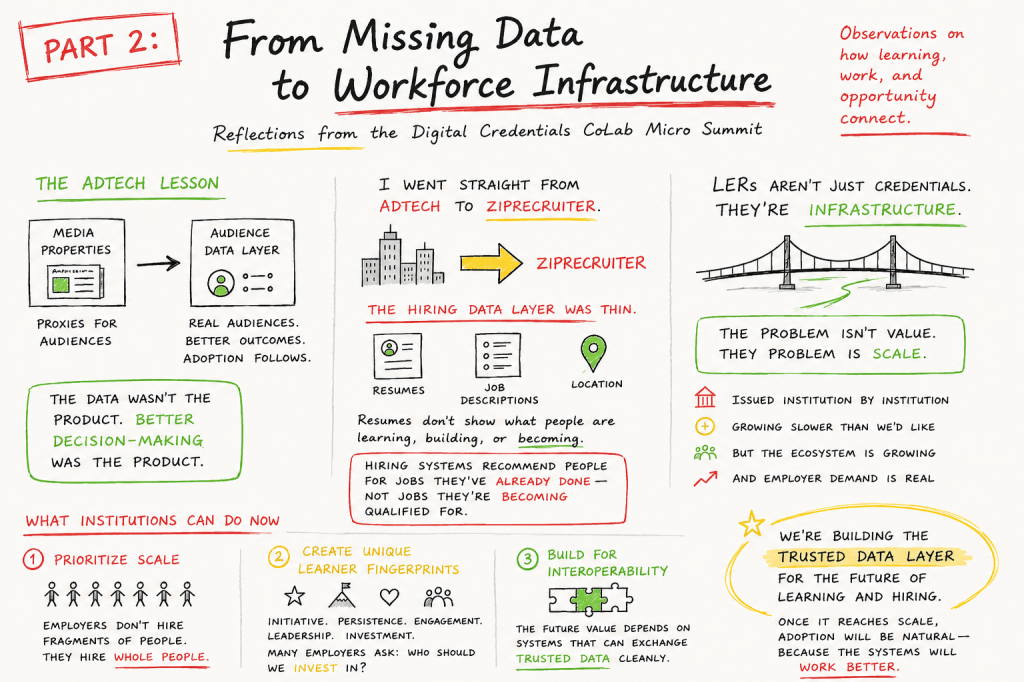
During my years in advertising technology, I watched the rise of programmatic advertising reshape the economics of media buying. Advertisers did not wake up one day asking for cookies or audience data infrastructure. They wanted better performance. Before scalable audience-level data existed, advertisers purchased media properties as proxies for audiences. If you wanted affluent business professionals, you bought the Wall Street Journal. If you wanted men between the ages of 18 and 54, you bought ESPN or Sports Illustrated.
But once scalable audience data emerged, the marketplace changed. Systems could identify actual audiences rather than relying on broad assumptions tied to media brands. Decision-making improved. Efficiency improved. Performance improved. Adoption followed naturally.
I think there is an important parallel emerging in hiring.
When I moved directly from advertising technology to ZipRecruiter, one of the things that immediately stood out to me was how little structured data hiring systems actually had access to. Most systems fundamentally operated on resumes, job descriptions, and location data. That was effectively the infrastructure underneath enormous portions of the labor market.
The problem is that resumes are incomplete representations of people. They tell us where someone has worked and perhaps where they went to school, but they reveal very little about how people are evolving, what they are learning, what skills they are developing, or what they may become qualified to do next. Hiring systems therefore tend to recommend people for jobs they have already done because those are the clearest signals available.
That started to change when we began experimenting with trusted learning and credential data through partnerships connected to organizations like Coursera and Grow With Google. When learners brought structured learning data into the marketplace, the impact was significant enough that internal teams repeatedly questioned the results because the patterns looked stronger than expected.
Engagement increased. Applications increased. Employers responded more positively to candidates. Invitations to apply increased. Marketplace performance improved.
The value was real.
The problem was scale.
At the time, only a relatively small percentage of job seekers had this kind of trusted structured learning data attached to their profiles. The signals were dramatically better, but the ecosystem itself was still too small to fundamentally reshape hiring workflows.
And honestly, I think that remains one of the defining realities of the Learning and Employment Record ecosystem today.
The biggest barrier is not employer demand for better signals.
The biggest barrier is that we are still building the infrastructure itself.
Unlike browser cookies, which scaled rapidly because a small number of browser providers could enable them centrally, Learning and Employment Records are growing institution by institution, issuer by issuer, and system by system. That is inherently slower. But it is still happening.
Every year more credentials are issued. More states are investing in digital identity infrastructure. More workforce systems are modernizing. More employers are struggling with fraud, verification, and signal quality inside hiring processes. More applicant tracking system providers are openly discussing the need for trusted and verifiable data infrastructure.
At the same time, I think there is an important opportunity for institutions to think more expansively about what learner records can become.
Too often, digital credentials still mirror traditional credentialing models. Large groups of learners complete a program and receive essentially identical representations of achievement. But employers do not hire categories. They hire people. Increasingly, they are trying to understand who demonstrates initiative, persistence, curiosity, leadership, engagement, and investment in their own growth.
Many employers are not simply asking who is qualified.
They are asking who they should invest in.
That creates an opportunity for institutions to recognize and structure a much richer set of learner signals. Leadership experiences, extracurricular involvement, mentorship, projects, career center participation, persistence, attendance, applied learning, and initiative are all meaningful indicators inside real-world hiring decisions. When we broaden the lens of what becomes portable trusted data, we create more complete learner fingerprints and more valuable hiring signals.
The other thing I emphasized during the session is that interoperability work happening today matters enormously. One of the greatest risks facing the ecosystem would be successfully reaching scale with infrastructure that cannot move cleanly between systems. The long-term value of Learning and Employment Records depends heavily on whether learning systems, identity systems, and hiring systems can exchange trusted data inside real workflows.
That is why I increasingly view this movement less as a credential movement and more as an infrastructure movement.
We are building the trusted data layer for the future of learning and hiring.
And once that infrastructure reaches sufficient scale and usability, employer adoption will not need to be forced through awareness campaigns or philosophical arguments about the value of credentials. It will emerge naturally because the systems themselves will simply perform better.


Leave a comment